Enrichment of lead-generation datasets with verified emails from Google SERP, achieving 4x coverage compared to Hunter and Clearbit
Get Started- 01 Input record
- 02 Google SERP API request
- 03 Parse and push
- 04 Name-to-email matching algorithm
- 05 QA
- 06 Dataset assembly and delivery

use case snapshot
Industry
Data-as-a-Service (DaaS), Web scraping
Use Case
Enriching lead-generation datasets with verified email addresses of professionals (lawyers, real-estate agents, dentists, chiropractors) sourced from Google SERP
Team Role
Data operations, product teams
Time to Value
A complete, enriched dataset of ~100,000 contacts is delivered in 1 day
Business Impact
Verified email addresses for ~80% of contacts in each dataset vs. ~20% with tools like Hunter or Clearbit
the strategic insight
Public professional directories such as Avvo, Realtor.com and WebMD provide rich profile data (names, phones, ratings, specialties), but they don’t expose email addresses, hiding them behind a login or pay wall that is illegal to scrape.
Combine that with the fact that about 80% of professionals — including real-estate agents, dentists and chiropractors — rely on personal Gmail, Yahoo or Outlook inboxes rather than company-domain emails. This means traditional enrichment tools like Hunter and Clearbit can find contact details for just about 20% of these professionals, because they only focus on business email addresses.
Here’s how HasData bridges this gap by:
- Scraping Google SERP results for every professional to surface emails published anywhere on the open web;
- Running a fuzzy-matching algorithm to confirm the email likely belongs to that individual;
- Delivering a fully public, fully compliant address that can be marketed to immediately.
The result: in just one day, you receive a complete, email-rich dataset that powers your product and equips your customers with a wealth of verified contacts for their lead generation and marketing campaigns.
Sergey Ermakovich
Co-founder and CMO at HasData
Context
Who
HasData’s own data ops and product team responsible for building and selling contact datasets on hasdata.com
Trigger moment
Users demanded email-complete lists; directories provided none, and scraping behind logins would violate policy
Initial attempts
and why they failed
Previous Approaches
- Scraping the directory directly
- Enrichment tools like Hunter and Clearbit
- Manual data collection
Limitations
- Email fields absent or hidden behind login/paywall
- Focus exclusively on business-domain email addresses, covering less than 20% target contacts
- Non-scalable beyond a few hundred records
The scraping
and enrichment workflow
01 Input record

Start with a baseline record collected from a public directory such as Avvo, Realtor.com or WebMD. Each record includes a professional’s full name, job role or specialty, city and state, phone number, website and other available fields.
02 Google SERP API request

- Compose a search string like: “{first} {last} {city} {role} email address”.
- Run the query via Google SERP API with num=100 to to retrieve a parsed JSON response containing 100 organic results along with rich snippets.
03 Parse and push
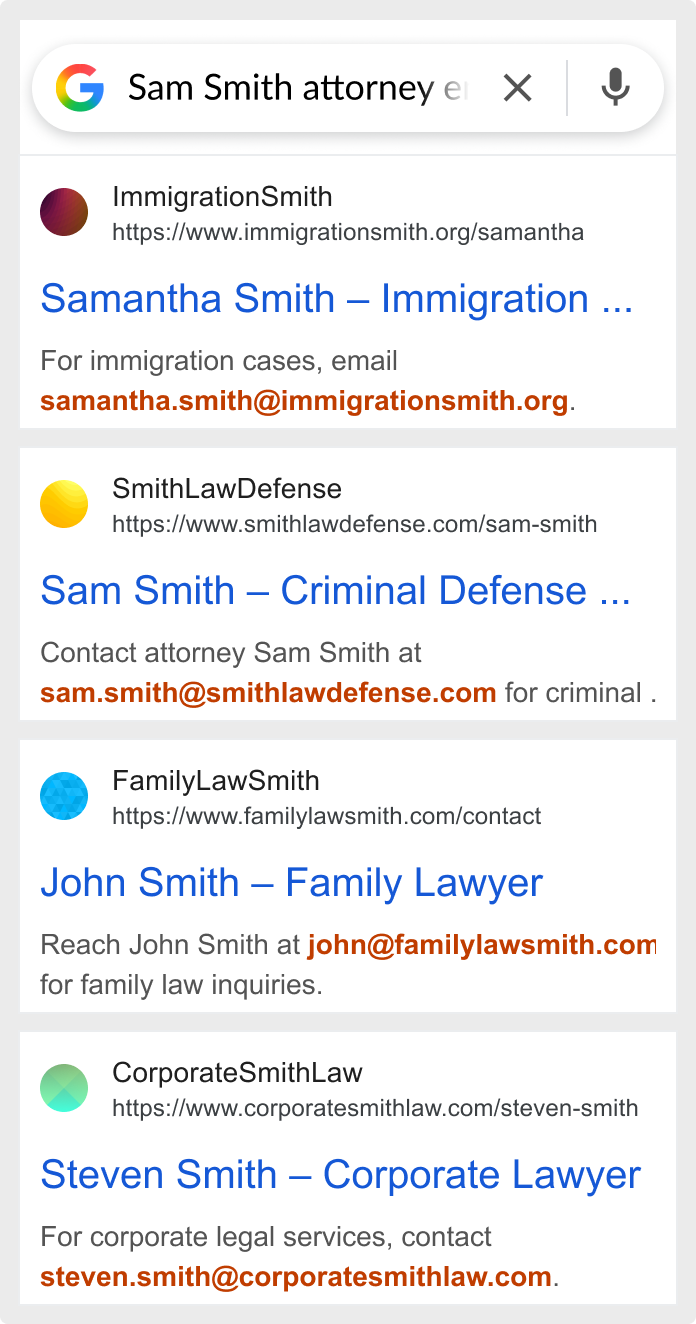
- Extract every string matching an email pattern from each organic result snippet as well as rich snippets like Knowledge Graph.
- Push all raw emails and associated metadata into HasData’s internal enrichment engine via an API endpoint.
- If no email is found, automatically retry Google SERP API request with:
- Synonyms (e.g., “lawyer” → “attorney,” “realtor” → “real estate agent”)
- Broader geography (expanding from city to state or state to country)
04 Name-to-email matching algorithm

- Break the name into parts. Split the full name (for example, “John M Smith”) into first, middle and last name. Generate initials (“jms”).
- Extract email components. For johnsmith@gmail.com, split into username (johnsmith) and domain (gmail.com).
- Check for matches using exact and fuzzy rules:
- Does the username contain the first, middle or last name?
- Does the username include the person’s initials? Is the username or domain very similar (small edit distance ≤ 2) to any part of the name?
- (Uses the fast-levenshtein npm package to detect small spelling differences.) Return true or false. If any rule passes, the email is flagged as likely belonging to that person. Otherwise, it is discarded.
05 QA

- All valid emails flow into a Google Sheet.
- A human analyst spot-checks a random selection; any false positives are flagged, and matching rules are adjusted as needed.
06 Dataset assembly and delivery

- The enrichment engine merges validated emails back into the baseline records.
- The final output is a roughly 100,000-contact, email-rich dataset delivered as a CSV or Google Sheet.
- Typical turnaround time: about 1 day from the first query to the final file.
outcomes
80% of the contact list was enriched with tens of thousands of verified emails, quadrupling what tools like Hunter and Clearbit delivered.
Customers received complete, email-rich datasets within days of payment, boosting satisfaction and driving repeat orders.
Why HasData
Legally compliant
No scraping of login-protected or paywalled content — all emails are collected only from publicly accessible pages, ensuring full legal and terms-of-service compliance.
Automated at scale
100,000 rows enriched in about 1 day with zero manual effort.
Accuracy first
Fuzzy algorithm filters look-alike emails and false positives.
Who else
can benefit?
Lead-generation agencies and SDR platforms
Access to fresh, accurate, and scalable data is key to building high-converting lead lists.
Recruiting and staffing firms sourcing niche talent
Finding specialized candidates often means going beyond LinkedIn and job boards.
B2B data providers and enrichment SaaS products (like Apollo and Clay)
Data enrichment tools thrive on comprehensive, up-to-date information.
Marketing & sales-intelligence teams seeking higher outreach hit-rates
Up-to-date, relevant data on companies and individuals improves targeting accuracy.
Testimonial
Using HasData internally to drive enrichment at scale validated the product’s reliability. The Google SERP API handled scale without breaking, the fuzzy-matching kept false positives low, and the automation let us process ~100k records in a day with no manual overhead. It’s the same infrastructure that powers both our operations and the value we deliver to customers.
Sergey Ermakovich
Co-founder and CMO at HasData