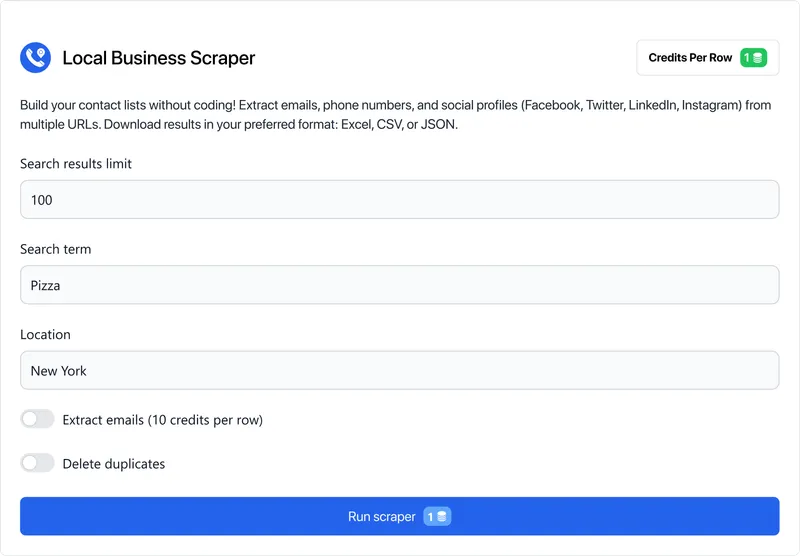
Local Business Scraper
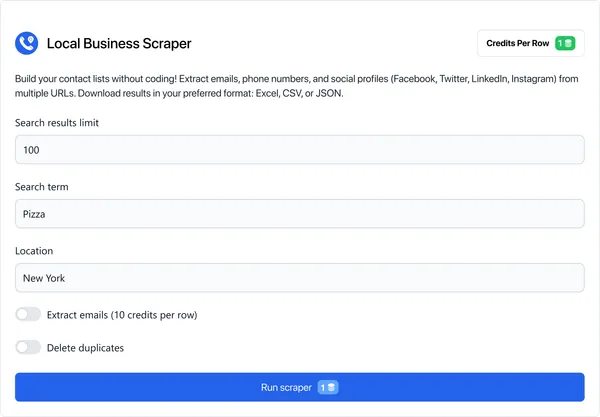
Extract valuable business data such as names, addresses, phone numbers, websites, ratings, and more from a wide range of local business directories. Download your results in user-friendly formats like CSV, JSON, and Excel for easy analysis.
- Real-Time Data
- No Blocks or CAPTCHAs
- Zero Coding
Why Automate Local Business Data Collection?
How to Automate the Lead Finding Process Without Coding
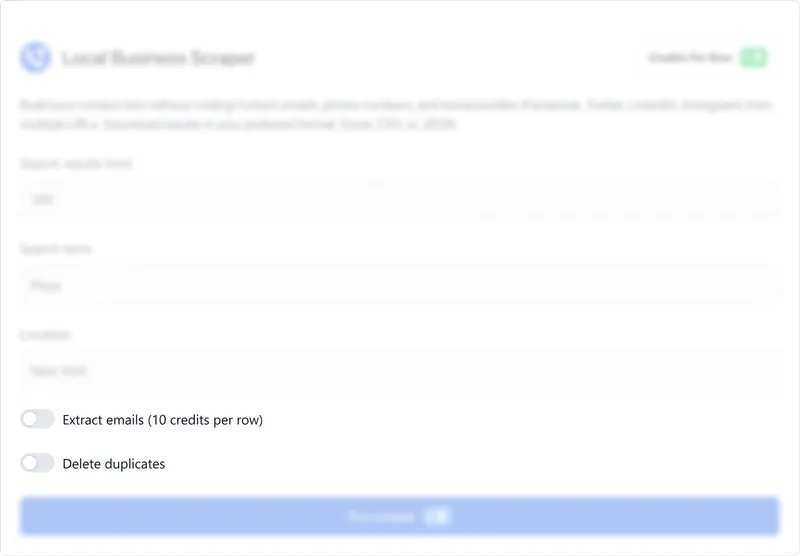
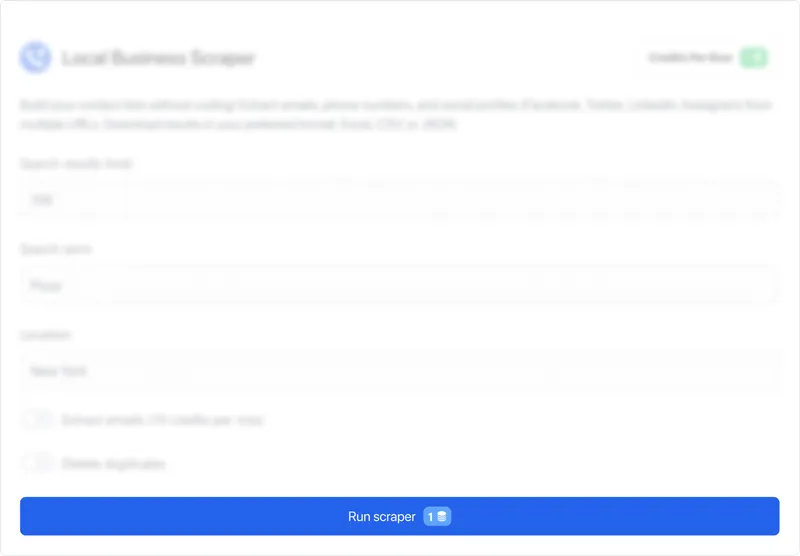
Use Cases for Scraping Local Businesses
Save time and energy by automating the task of extracting business listings to focus on other important tasks that require your attention.
Lead Scraping
Gather contact information for potential customers, such as names, phone numbers, and email addresses, to expand your customer base and generate new leads.
Competitive Analysis
Get insight into your competitors' pricing, promotions, product offerings, and customer ratings to improve your operations and gain a competitive edge.
Location Intelligence
Understand consumer behavior and preferences in different geographic areas to identify areas with high potential for business growth.
Competitor Growth Analysis
Track the growth in the number of local businesses of a competitor to identify areas where the competitor is expanding and assess their success level in those areas.
Our Advantages
Our scrapers are designed for ease of use and efficiency, making them the perfect choice for anyone looking to quickly and easily gather data from Lead Scraper
- Time savings
Don't waste time building and testing your own scraper
- Industry Expertise
Our experience allows us to create more efficient and reliable solutions
- Support
Get access to customer support to help you get the most out of the tool
- Low Cost
Building your own scraper can be costly, especially if you need to hire developers
- Scalability
Get more data from different sources without having to create new scrapers
- Regular Update
Our parsers are regularly updated to ensure they are compatible with Apartments.com website changes
- Real-Time Data
Get real-time access to the latest data from Apartments.com without relying on outdated datasets
- Never Get Blocked
Get reliable data extraction without ever getting blocked or having to solve CAPTCHA
Related Scrapers
Discover other powerful scrapers to streamline your data extraction efforts.
Google Maps Scraper
Effortlessly extract Google Maps data – business types, phone numbers, addresses, websites, emails, ratings, review counts, and more. No coding needed! Download results in convenient JSON, CSV, and Excel formats.
Google SERP Scraper
Discover the easiest way to get valuable SEO data from Google SERPs with our Google SERP Scraper! No coding is needed - just run, download, and analyze your SERP data in Excel, CSV, or JSON formats. Get started now for free!
Google Maps Reviews Scraper
Effortlessly scrape and analyze customer reviews from Google Maps to gain actionable insights into customer sentiment, identify areas for improvement, and enhance your brand reputation. No coding expertise required! Easily download your data in Excel, CSV, or JSON formats for simple analysis and use.
Simple Transparent Pricing
Flexible pricing plans that are ready to scale with your business.
Try Local Business Scraper for Free for 30 Days!
The easiest way to scrape Local Businesses without writing a line of code.
Startup
$49 /month
Try For Free- Up to 200,000 data rows
- Priority email support
- Data export to CSV, Excel, and JSON formats
Business
$99 /month
Try For Free- Up to 1,000,000 data rows
- Personal manager
- Data export to CSV, Excel, and JSON formats
Enterprise
$249 /month
Try For Free- Up to 3,000,000 data rows
- Personal manager
- Data export to CSV, Excel, and JSON formats
Why people use HasData
See why we in demand
- Start for free, pay as you go
- Integrate with 7,000+ applications
- Universal solution for everyone
- Saves time and money
- Personalized support
- Efficiency and reliability
- Flexibility for different tasks and budgets
- Ease of use
Frequently Asked Questions
Let us answer the most asked questions about Lead Scraper and HasData.
Local Business Scraper is a tool designed to automate the lead-finding process from business directories. Quickly collect essential business information such as reviews, ratings, contact details, operating hours, and more, saving you countless hours of manual research.
No, you do not need to install any software or browser extension to use our scraper. We provide a cloud-based service, so all the processing is done on our servers. You can even close our website and go about your business while our scraper is running. This gives you the freedom to focus on other tasks while your data is being extracted.
The data extraction process starts as soon as you send the request. The duration of the extraction will depend on the amount of information you need to retrieve and can range from a few seconds to several minutes.
One row of data for this scraper costs 1 credit.
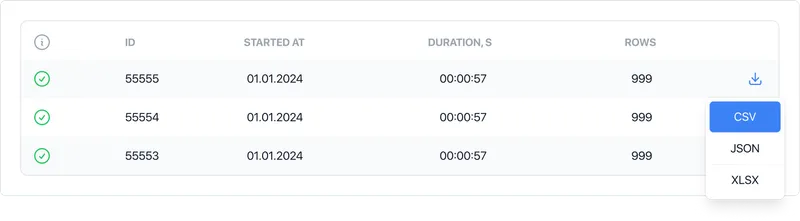
We provide data in CSV, Excel, and JSON formats.
You can contact our support using the feedback form or the online support widget.
We regularly check the performance of our scrapers and update them if necessary to provide users with correct data.
It is legal to scrape publicly available data such as business names, addresses, phone numbers, or ratings if you use these data for research or personal use.
No, it's completely free and requires no credit card if you use the free plan for 1,000 API credits. You can use them for a month. If you need more, you can use any other paid plan.
Contact us at [email protected] and we'll create a custom service package according to your requirements.
Yes, you can cancel your subscription plan at any time. You can do this in 10 seconds from your dashboard. Once you cancel your subscription, there are no recurring payments.